import gym import math import random import numpy as np import matplotlib import matplotlib.pyplot as plt from collections import namedtuple from itertools import count from PIL import Image import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import torchvision.transforms as T env = gym.make('CartPole-v0',render_mode='rgb_array').unwrapped # set up matplotlib is_ipython = 'inline'in matplotlib.get_backend() if is_ipython: from IPython import display plt.ion() # if gpu is to be used device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
输出为(此处的输出表示CartPole-v0已经过时,希望我使用CartPole-v1)
1 2
C:\Users\13015\anaconda3\envs\pytorch\lib\site-packages\gym\envs\registration.py:555: UserWarning: WARN: The environment CartPole-v0 is out of date. You should consider upgrading to version `v1`. logger.warn(
resize = T.Compose([T.ToPILImage(), T.Resize(40, interpolation=Image.CUBIC), T.ToTensor()]) defget_cart_location(screen_width): world_width = env.x_threshold * 2 scale = screen_width / world_width returnint(env.state[0] * scale + screen_width / 2.0) # MIDDLE OF CART defget_screen(): # Returned screen requested by gym is 400x600x3, but is sometimes larger # such as 800x1200x3\. Transpose it into torch order (CHW). screen = env.render().transpose((2, 0, 1)) # Cart is in the lower half, so strip off the top and bottom of the screen _, screen_height, screen_width = screen.shape screen = screen[:, int(screen_height*0.4):int(screen_height * 0.8)] view_width = int(screen_width * 0.6) cart_location = get_cart_location(screen_width) if cart_location < view_width // 2: slice_range = slice(view_width) elif cart_location > (screen_width - view_width // 2): slice_range = slice(-view_width, None) else: slice_range = slice(cart_location - view_width // 2, cart_location + view_width // 2) # Strip off the edges, so that we have a square image centered on a cart screen = screen[:, :, slice_range] # Convert to float, rescale, convert to torch tensor # (this doesn't require a copy) screen = np.ascontiguousarray(screen, dtype=np.float32) / 255 screen = torch.from_numpy(screen) # Resize, and add a batch dimension (BCHW) return resize(screen).unsqueeze(0).to(device)
C:\Users\13015\AppData\Local\Temp\ipykernel_21056\1707259767.py:2: DeprecationWarning: CUBIC is deprecated and will be removed in Pillow 10 (2023-07-01). Use BICUBIC or Resampling.BICUBIC instead. T.Resize(40, interpolation=Image.CUBIC), C:\Users\13015\anaconda3\envs\pytorch\lib\site-packages\torchvision\transforms\transforms.py:329: UserWarning: Argument 'interpolation' of typeintis deprecated since 0.13and will be removed in0.15. Please use InterpolationMode enum. warnings.warn(
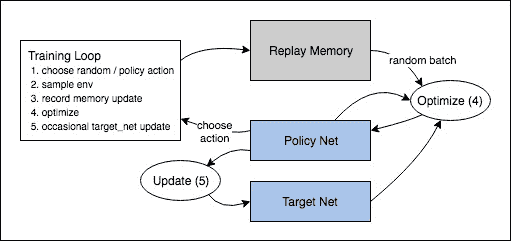
BATCH_SIZE = 128 GAMMA = 0.999 EPS_START = 0.9 EPS_END = 0.05 EPS_DECAY = 200 TARGET_UPDATE = 10 # 获取屏幕大小,以便我们可以根据从ai-gym返回的形状正确初始化层。 # 这一点上的平常尺寸接近3x40x90,这是在get_screen()中抑制和缩小的渲染缓冲区的结果。 init_screen = get_screen() _, _, screen_height, screen_width = init_screen.shape # Get number of actions from gym action space n_actions = env.action_space.n policy_net = DQN(screen_height, screen_width, n_actions).to(device) target_net = DQN(screen_height, screen_width, n_actions).to(device) target_net.load_state_dict(policy_net.state_dict()) target_net.eval() optimizer = optim.RMSprop(policy_net.parameters()) memory = ReplayMemory(10000) steps_done = 0 defselect_action(state): global steps_done sample = random.random() eps_threshold = EPS_END + (EPS_START - EPS_END) * \ math.exp(-1. * steps_done / EPS_DECAY) steps_done += 1 if sample > eps_threshold: with torch.no_grad(): # t.max(1) will return largest column value of each row. # second column on max result is index of where max element was # found, so we pick action with the larger expected reward. return policy_net(state).max(1)[1].view(1, 1) else: return torch.tensor([[random.randrange(n_actions)]], device=device, dtype=torch.long) episode_durations = [] defplot_durations(): plt.figure(2) plt.clf() durations_t = torch.tensor(episode_durations, dtype=torch.float) plt.title('Training...') plt.xlabel('Episode') plt.ylabel('Duration') plt.plot(durations_t.numpy()) # Take 100 episode averages and plot them too iflen(durations_t) >= 100: means = durations_t.unfold(0, 100, 1).mean(1).view(-1) means = torch.cat((torch.zeros(99), means)) plt.plot(means.numpy()) plt.pause(0.001) # pause a bit so that plots are updated if is_ipython: display.clear_output(wait=True) display.display(plt.gcf())
num_episodes = 50 for i_episode inrange(num_episodes): # Initialize the environment and state env.reset() last_screen = get_screen() current_screen = get_screen() state = current_screen - last_screen for t in count(): # Select and perform an action action = select_action(state) _,reward,done,_,_ = env.step(action.item()) reward = torch.tensor([reward], device=device) # Observe new state last_screen = current_screen current_screen = get_screen() ifnot done: next_state = current_screen - last_screen else: next_state = None # Store the transition in memory memory.push(state, action, next_state, reward) # Move to the next state state = next_state # Perform one step of the optimization (on the target network) optimize_model() if done: episode_durations.append(t + 1) plot_durations() break # Update the target network, copying all weights and biases in DQN if i_episode % TARGET_UPDATE == 0: target_net.load_state_dict(policy_net.state_dict()) print('Complete') env.render() env.close() plt.ioff() plt.show()