from __future__ import print_function #%matplotlib inline import argparse import os import random import torch import torch.nn as nn import torch.nn.parallel import torch.backends.cudnn as cudnn import torch.optim as optim import torch.utils.data import torchvision.datasets as dset import torchvision.transforms as transforms import torchvision.utils as vutils import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML
# Lists to keep track of progress img_list = [] G_losses = [] D_losses = [] iters = 0
print("Starting Training Loop...") # For each epoch for epoch inrange(num_epochs): # 对于数据加载器中的每个batch for i, data inenumerate(dataloader, 0):
############################ # (1) Update D network: maximize log(D(x)) + log(1 - D(G(z))) ########################### ## Train with all-real batch netD.zero_grad() # Format batch real_cpu = data[0].to(device) b_size = real_cpu.size(0) label = torch.full((b_size,), real_label, device=device) # Forward pass real batch through D output = netD(real_cpu).view(-1) # Calculate loss on all-real batch label = label.to(torch.float) errD_real = criterion(output, label) # Calculate gradients for D in backward pass errD_real.backward() D_x = output.mean().item()
## Train with all-fake batch # Generate batch of latent vectors noise = torch.randn(b_size, nz, 1, 1, device=device) # Generate fake image batch with G fake = netG(noise) label.fill_(fake_label) # Classify all fake batch with D output = netD(fake.detach()).view(-1) # Calculate D's loss on the all-fake batch errD_fake = criterion(output, label) # Calculate the gradients for this batch errD_fake.backward() D_G_z1 = output.mean().item() # Add the gradients from the all-real and all-fake batches errD = errD_real + errD_fake # Update D optimizerD.step()
############################ # (2) Update G network: maximize log(D(G(z))) ########################### netG.zero_grad() label.fill_(real_label) # fake labels are real for generator cost # Since we just updated D, perform another forward pass of all-fake batch through D output = netD(fake).view(-1) # Calculate G's loss based on this output errG = criterion(output, label) # Calculate gradients for G errG.backward() D_G_z2 = output.mean().item() # Update G optimizerG.step()
# Output training stats if i % 50 == 0: print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f' % (epoch, num_epochs, i, len(dataloader), errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# Save Losses for plotting later G_losses.append(errG.item()) D_losses.append(errD.item())
# Check how the generator is doing by saving G's output on fixed_noise if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)): with torch.no_grad(): fake = netG(fixed_noise).detach().cpu() img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
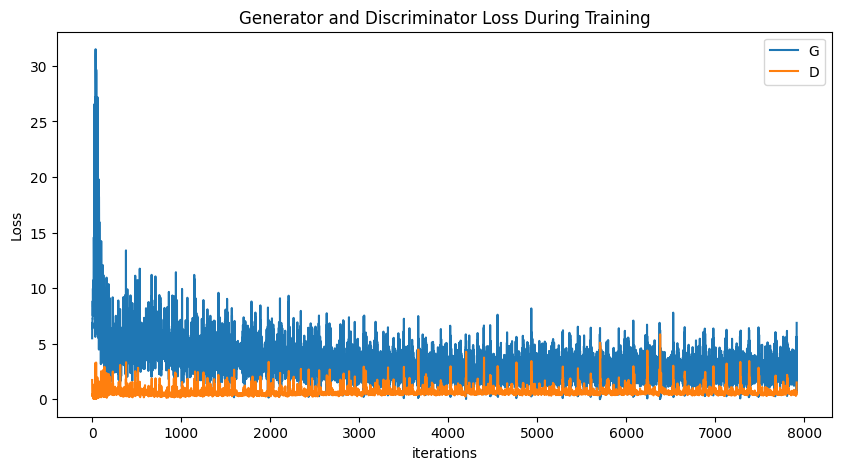
plt.figure(figsize=(10,5)) plt.title("Generator and Discriminator Loss During Training") plt.plot(G_losses,label="G") plt.plot(D_losses,label="D") plt.xlabel("iterations") plt.ylabel("Loss") plt.legend() plt.show()
G的过程可视化
记住在每个训练epoch之后我们如何在fixed_noise batch中保存生成器的输出
现在,我们可以通过动画可视化G的训练进度。按播放按钮开始动画
本文结果是在jupyter notebook运行得到的,部分环境下可能无法可视化G的训练进度
1 2 3 4 5 6
fig = plt.figure(figsize=(8,8)) plt.axis("off") ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list] ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)