
Scrapy爬虫
Scrapy初步认识
Scrapy模块安装
首先,我们需要先搭建好Scrapy的环境
利用conda创建一个名为Scrapy_work的虚拟环境并且进入该环境
1 | conda create -n "Scrapy_work" |
然后使用pip安装Scrapy模块
1 | pip install Scrapy |
为了确认Scrapy模块已经安装成功,可以在Python当中测试一下能否导入Scrapy模块
1 | import scrapy |
如果正确安装的话,终端会显示Scrapy的版本
编写Scrapy爬虫
Scrapy框架结构及其工作原理
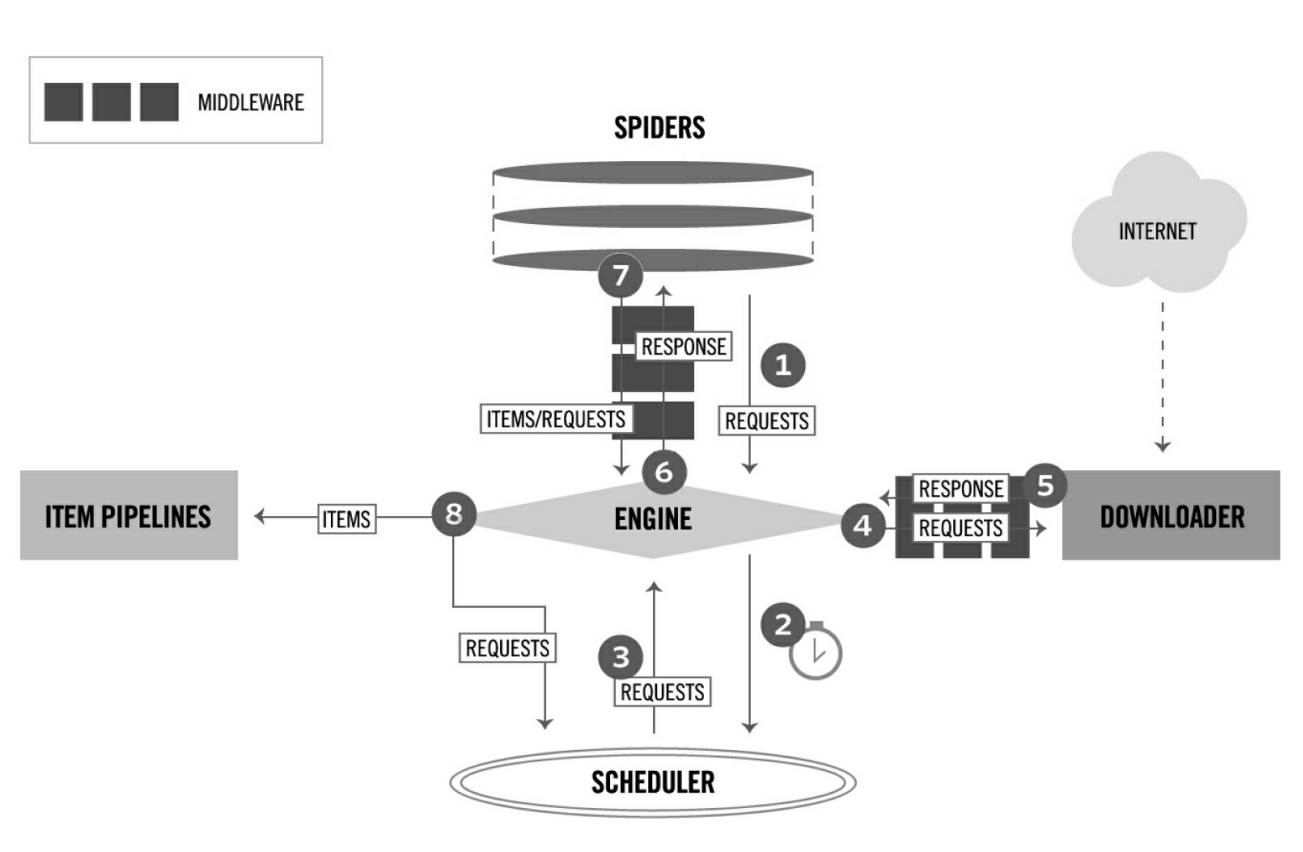
上图为Scrapy框架是组成结构
Scrapy框架中的各个组件的介绍如下所示
| 组件 | 描述 | 类型 |
|---|---|---|
| ENGINE | 引擎,框架的核心,其他所有组件在其控制下协同工作 | 内部组件 |
| SCHEDULER | 调度器,负责对SPIDER提交的下载请求进行调度 | 内部组件 |
| DOWNLOADER | 下载器,负责下载页面(发送HTTP请求和接收HTTP响应) | 内部组件 |
| SPIDER | 爬虫,负责提取页面中的数据,并产生对新页面的下载请求 | 用户实现 |
| MIDDLEWARE | 中间件,负责对Request对象和Response对象进行处理 | 可选组件 |
| ITEM PIPELINE | 数据管道,负责对爬取到的数据进行处理 | 可选组件 |
对于用户来说,Spider是最核心的组件,爬虫的开发都是围绕Spider组件展开的
接下来是框架中的数据流
| 对象 | |
|---|---|
| REQUEST | Scrapy的HTTP请求对象 |
| RESPONSE | Scrapy的HTTP响应对象 |
| ITEM | 从页面中爬取的一项数据 |
数据的流动过程简述如下:
- 当
SPIDER要爬取某URL地址的页面时,需要使用该URL构造一个Request对象,提交给ENGINE Request对象随后进入SCHEDULER按某种算法进行排队,之后的某个时刻SCHEDULER将其出队,送往DOWNLOADERDOWNLOADER根据Request对象中的URL地址发送一次HTTP请求到网站的服务器,之后用服务器返回的HTTP响应构造出一个Response对象,其中包含页面的HTML文本Response对象最终会被送到SPIDER的页面解析函数处进行处理,页面解析函数可以从页面中提取数据,并且封装为ITEM之后提交给ENGINE,之后被送往ITEM PIPELINE进行处理,最后由EXPORTER以某种数据格式写入文件;除此之外,页面解析函数还可以从页面中提取链接,构造出一个新的Request对象提交给ENGINE
Request和Response对象
Request对象
1 | class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback, flags]) |
- url:请求页面的url地址
- callback:页面解析函数,
Request对象请求的页面在下载完成之后,由该参数指定的页面解析函数被调用,如果未传递该参数,则默认调用Spider的parse方法 - method:HTTP请求的方法,默认为
GET - headers:HTTP请求的头部字典,dict类型
- body:HTTP请求的正文
- cookies:Cookies信息字典,dict类型
- meta:Request的元数据字典,用于给框架中其他组件传递信息
- encoding:url和body参数的编码默认为
UTF-8,如果传入的参数是str类型,则使用该参数进行编码 - priority:请求的优先级默认值为0,优先级高的请求优先下载
- dont_filter:如果对同一个url地址多次提交下载请求,后面的请求会被屏蔽,将此参数设置为
True可以避免请求被过滤,强制下载 - errback:请求出现异常或者出现HTTP错误时的回调函数
- flag:一个Request请求的标记,一般用于log记录
Response对象
Response对象是用来描述一个HTTP响应的,Response只是一个基类,根据响应内容的不同有如下子类:
- TextResponse
- HtmlResponse
- XmlResponse
当一个页面下载完成后,下载器就依据HTTP响应头部中的Content-Type信息创建某个Response的子类对象
1 | class scrapy.http.Response(url[, status=200, headers=None, body=b'', flags=None, request=None]) |
- url:HTTP响应的url地址
- status:HTTP响应的状态码
- headers:HTTP响应的头部,类字典类型,可以用
get或getlist方法进行访问,例如:
1 | response.headers.get('Content-Type') |
- body:HTTP响应正文
- text:文本形式的HTTP响应正文
- encoding:HTTP响应正文的编码
- request:产生该HTTP响应的
Request对象 - meta:即
response.request.meta - selector:用于在
Response中提取数据 - xpath:使用XPath选择器在
Response中提取数据 - css:使用CSS选择器在
Response中提取数据 - urljoin:用于构造绝对url
Spider开发流程
一般而言,实现一个Spider只需要以下几个步骤:
- 继承
scrapy.Spider - 为
Spider取名 - 设置起始的爬取点
- 实现页面解析函数
使用Selector提取数据
我们要从页面中提取数据需要进行HTTP文本解析,一般用以下模块进行处理:
- BeautifulSoup
- lxml
Scrapy综合以上两者的优点实现了Selector类
在Scrapy中使用Selector对象提取页面中的数据,使用前先通过选择器选中页面中需要提取的数据,然后进行提取
Selector对象
Selector类的实现位于scrapy.selector模块
创建对象
我们可以将页面的HTML文档字符串传递给Selector构造器方法的text参数
也可以使用一个Response对象构造Selector对象,将其传递给Selector构造器方法的response参数
选中数据
调用Selector对象的XPath方法或CSS方法,可以选中文档中的某个或某些部分
XPath方法和CSS方法返回一个SelectorList对象,其中包含每个被选中部分对应的Selector对象
SelectorList对象也有XPath和CSS方法,但是不同的是这里的方法是调用SelectorList对象当中的每一个Selector对象的XPath和CSS方法,并将结果收集到一个新的SelectorList对象当中,然后返回给用户
提取数据
调用Selector或SelectorList对象的以下方法可以将选中的内容提取出来
extract()re()extract_first()(SelectorList对象专有,提取第一个Selector对象的数据)re_first()(SelectorList对象专有,对第一个Selector对象进行正则匹配)
Response内置Selector
在我们实际的开发中,一般不需要手动创建Selector对象
因为在第一次访问一个Response对象的selector属性时,Response对象内部会以自身为参数自动创建Selector对象,并将该对象缓存,以便下次使用
为了方便,Response对象还内置了XPath和CSS方法,它们会在内部调用内置Selector对象的XPath和CSS方法
Xpath
Xpath即XML路径语言,它是一种用来确定XML文档中某部分位置的语言
XML文档的节点有多种类型,其中最常用的有以下几种:
- 根节点(整个文档树的根)
- 元素节点(html,body,div,p,a)
- 属性节点(href)
- 文本节点(正文)
节点之间的关系有以下几种:
- 父子
- 兄弟
- 祖先/后裔
基础语法
下表列出了XPath常用的基本语法
| 表达式 | 描述 |
|---|---|
| / | 选中文档的根 |
| . | 选中当前节点 |
| … | 选中当前节点的父节点 |
| ELEMENT | 选中子节点中所有的ELEMENT元素节点 |
| //ELEMENT | 选中后代节点中所有ELEMENT元素节点 |
| * | 选中所有元素子节点 |
| text() | 选中所有文本子节点 |
| @ATTR | 选中名为ATTR的属性节点 |
| @* | 选中所有属性节点 |
| [谓语] | 谓语用来查找某个特定的节点或者包含某个特定值的节点 |
常用函数
XPath还提供许多函数,如数字,字符串,时间,日期,统计等等,例如:
- position() 选中指定位置
- last() 选中最后一个
- string() 返回参数的字符串值
- contains(str1,str2) 判断str1中是否包含str2,返回bool值
CSS选择器
基础语法
| 表达式 | 描述 | 例子 |
|---|---|---|
| * | 选中所有元素 | * |
| E | 选中E元素 | p |
| E1,E2 | 选中E1和E2元素 | div,pre |
| E1 E2 | 选中E1后代元素中的E2元素 | div p |
| E1>E2 | 选中E1子元素中的E2元素 | div>p |
| E1+E2 | 选中E1兄弟元素中的E2元素 | p+strong |
| .CLASS | 选中CLASS属性包含CLASS的元素 | .info |
| #ID | 选中id属性为ID的元素 | #main |
| [ATTR] | 选中包含ATTR属性的元素 | [href] |
| [ATTR=VALUE] | 选中包含ATTR属性且值为VALUE的元素 | [method=post] |
| [ATTR~=VALUE] | 选中包含ATTR属性且值包含VALUE的元素 | [class~=clearfix] |
| E:nth-child(n) E:nth-last-child(n) |
选中E元素,且该元素必须是其父元素的(倒数)第n个子元素 | a:nth-child(1) |
| E:first-child E:last-child |
选中E元素,且该元素必须是其父元素的(倒数)第一个子元素 | a:first-child |
| E:empty | 选中没有子元素的E元素 | div:empty |
| E::text | 选中E元素的文本节点 | p::text |
使用Item封装数据
我们在存储数据的时候,经常会使用字典进行存储,但是字典会有以下的缺点:
- 无法一目了然地了解数据当中的字段,影响代码可读性
- 缺乏对字段名字的检测,容易因为笔误而出错
- 不便于携带元数据(传递给其他组件的信息)
Item和Field
Scrapy定义了两个类,用户可以用它们自定义数据类,封装爬取到的信息:
Item基类:自定义数据类的基类Field类:用来描述自定义数据类型包含哪些字段(如name,price等)
1 | from scrapy import Item,Field |
拓展Item子类
有时候如果需要对已经自定义的数据类进行拓展的话,可以直接继承之前的类,然后在定义中加入新的Field
使用Item Pipeline处理数据
Item Pipeline是负责处理数据的组件,在一个项目中可以同时启用多个Item Pipeline,按照指定次序级联起来,形成一条数据流水线
以下是几种典型应用:
- 清洗数据
- 验证数据的有效性
- 过滤掉重复的数据
- 将数据存入数据库
Item Pipeline
在创建一个Scrapy项目时,会自动生成一个pipelines.py文件,它用来存放用户自定义的Item Pipeline
Item Pipeline不需要继承特定的基类,只需要实现特定的方法即可
一个Item Pipeline必须实现一个process_item(item,spider)方法
其中item是爬取到的一项数据,Spider是爬取到此数据的Spider对象
如果
process_item(item,spider)在处理某项item时返回了一项数据,返回的数据会递送给下一级Item Pipeline继续处理如果
process_item(item,spider)在处理某项item时抛出了一个DropItem异常,则该项item会被抛弃,不再递送给后面的Item Pipeline进行处理
除了必须实现的process_item(item,spider)之外,还有3个比较常用的方法:
open_spider(self,spider)在Spider打开时回调该方法,常用于初始化,如连接数据库close_spider(self,spider)在Spider关闭时回调该方法,常用于处理完所有数据之后的清理工作,如关闭数据库from_crawler(cls,crawler)创建Item Pipeline时回调该方法,通常通过crawler.settings读取配置,根据配置创建Item Pipeline对象
在Scrapy中,Item Pipeline是可选的组件,想要启用的时候需要在settings.py中进行配置
使用LinkExtractor提取链接
一般而言,提取链接有两种方法:
- 使用Selector
- 使用LinkExtractor
当需要提取大量链接或提取的规则比较复杂时,使用LinkExtractor更加方便
使用LinkExtractor
一般使用LinkExtractor模块的流程如下:
- 导入
LinkExtractor模块 - 创建一个
LinkExtractor对象,使用一个或多个构造器参数描述提取规则 - 调用
LinkExtractor对象的extract_links方法,并传入一个Response对象,该方法会依据创建对象时的提取规则去从Response对象包含的页面中提取链接,并返回一个由绝对url构成的列表,可以用其直接构造Request对象
描述提取规则
1 | classscrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(), deny_extensions=None, restrict_xpaths=(), restrict_css=(), tags=('a', 'area'), attrs=('href', ), canonicalize=False, unique=True, process_value=None, strip=True) |
在Scrapy早期的版本中也有其他的
LinkExtractor类,但是现在它们被弃用了
allow接收一个正则表达式或者正则表达式列表,用于提取绝对url,如果该参数为空则提取全部链接deny接收一个正则表达式或者正则表达式列表,用于排除匹配的urlallow_domains接收一个域名或者域名列表,提取到指定域的链接deny_domains接收一个域名或者域名列表,排除到指定域的链接deny_extensions在接收时需要忽略的扩展名restrict_xpaths接收一个XPath表达式或表达式列表,提取XPath表达式选中区域下的链接restrict_css接收一个CSS选择器或选择器列表,提取CSS选择器选中区域下的链接tag接收一个标签或标签列表,提取指定标签内的链接attrs接收一个属性或一个属性列表,提取指定属性内的链接canonicalize对提取的url进行规范化处理,常设置为Falseunique是否应对提取的链接进行重复过滤process_value接收一个形如func(value)的回调函数,LinkExtractor将会调用该回调函数对提取的每一个链接进行处理strip是否从提取的属性中去除空格,因为LinkExtractor会自动去除空格
使用Exporter导出数据
在Scrapy中,负责导出数据的组件被称为Exporter
Scrapy实现了多个Exporter,每个Exporter支持一种数据格式的导出,支持的数据格式如下所示:
- JSON
- JSON lines
- CSV
- XML
- Pickle
- Marshal
如果需要导出为其他数据,则需要自己实现Exporter
指定导出数据
在导出数据时,需要向爬虫提供以下信息:
- 导出文件的路径
- 导出的数据格式
在配置文件中,经常用到以下几个选项:
FEED_URL导出文件的路径FEED_FORMAT导出的数据格式FEED_EXPORT_ENCODING导出文件编码
默认情况下JSON文件使用数字编码,其他使用UTF-8编码
FEED_EXPORT_FIELDS导出数据包含的字段(默认导出所有字段),并指定次序FEED_EXPORTERS用户定义新的Exporter字典,添加新的导出数据格式的时候使用
用户自定义的导出数据格式的代码编写此处不赘述,略
下载文件和图片
下载文件也是爬虫很常用的一种需求,例如图片,视频,文档,压缩包等等
Scrapy框架内置了两个Item Pipeline专门用于下载文件和图片
FilesPipelineImagesPipeline
FilesPipeline的使用
FilesPipeline的使用步骤一般如下所示:
- 在配置文件
settings.py中启用FilesPipeline,通常是将其置于其他的Item Pipeline之前 - 在配置
settings.py时,使用FILES_STORE指定文件的下载目录 - 在Spider解析一个包含文件下载链接的页面时,将所有需要下载文件的url地址收集到一个列表中,然后赋值给
item的file_urls字段(item[‘file_urls’])
FilesPipeline在处理每一项item时都会进行读取,然后对其中的每一个url进行下载
当FilesPipeline下载完所有的文件后,就会将下载的结果信息存储到另一个列表中去,下载的结果包含以下内容:
- 文件下载到本地的路径
- Checksum文件的校验和
- url文件的url地址
ImagesPipeline的使用
图片的本质也是文佳,ImagesPipeline是FilesPipeline的子类,使用上大同小异,只是配置的选项上有细微的差别
| FilesPipeline | ImagesPipeline | |
|---|---|---|
| 导入路径 | scrapy.pipelines.files.FilesPipeline | scrapy.pipelines.images.ImagesPipeline |
| Item字段 | file_urls,files | image_urls,images |
| 下载目录 | FILES_STORE | IMAGES_STORE |
ImagesPipeline在FilesPipeline的基础上针对图片增加了一些特有的功能
- 为下载的图片生成缩略图
要开启此功能,只需要在配置文件settings.py中设置IMAGES_THUMBS,例如:
1 | IMAGES_THUMBS = { |
- 过滤掉尺寸较小的图片
开启该功能需要在配置文件settings.py中设置IMAGES_MIN_WIDTH和IMAGES_MIN_HEIGHT,它们分别指定最小尺寸的图片的宽和高,例如:
1 | IMAGES_MIN_WIDTH = 110 |
模拟登录
目前,大部分网站都需要登录才能获取资源,所以有时候爬虫需要先模仿用户登录,再去爬取内容
登录的实质就是向服务器发送含有登录表单数据的HTTP请求(通常是POST),Scrapy提供了一个FormRequest类,专门用于构造含有表单数据的请求
Scrapy的登录模块
FormRequest的构造器方法有一个formdata参数,接收字典形式的表单数据
我们还可以直接调用FormRequest的from_response方法,调用时需要传入一个Response对象作为一个参数,该方法会解析Response对象中所包含页面中的<form>元素,帮助用户创建FormRequest对象,并自动填入表单数据,我们只需要通过formdata参数将账号和密码填入即可
识别验证码
目前很多网站为了防止爬虫爬取,登录的时候需要用户输入验证码,一般有以下几种方法去识别验证码:
- OCR识别
我们可以使用Python的第三方库进行识别(例如tesseract-ocr)
- 网络平台API
也可以去验证码识别平台购买相关服务套餐,接入API
- 人工识别
在其他方法不管用的时候,我们也可以等Scrapy下载完验证码图片后,调用Image.show方法来显示图片,然后再调用Python内置的input函数来捕获用户的输入
Cookie登录
我们不需要去研究各个浏览器将Cookie以何种形式存储在何处,只需要调用第三方库browsercookie即可获得Chorme和Firefox浏览器中的Cookie
爬取动态页面
我们之前讨论的都是静态页面的信息爬取,但是在实际应用中,大多数页面都是动态页面,页面中的部分内容是需要运行页面中的JavaScript脚本动态生成的,爬取相对困难
实际中更常见的是JavaScript通过HTTP请求跟网页动态交互获取数据(Ajax),然后使用数据去更新HTML页面
爬取此类网站需要先执行页面中的JavaScript代码去渲染页面,然后再进行爬取
Splash渲染引擎
Splash是Scrapy官方推荐的JavaScript渲染引擎,提供基于HTTP端口的JavaScript渲染服务,支持以下的功能:
- 为用户返回经过渲染的HTML页面或者页面截图
- 并发渲染多个页面
- 关闭图片加载,加速渲染
- 在页面中执行用户自定义的JavaScript代码
- 执行用户自定义的渲染脚本(lua)
Splash的功能丰富,包含了多个服务端点,此处仅介绍两个最常用的端点:
- render.html 提供JavaScript页面渲染服务
- execute 执行用户自定义的渲染脚本(lua),利用该端点可以在页面中执行JavaScript代码
render.html端点
| 服务端点 | render.html |
|---|---|
| 请求地址 | http://localhost:8050/render.html |
| 请求方式 | GET / POST |
| 返回类型 | HTML |
render.html端点支持的参数如下表所示(仅列出常用的参数)
| 参数 | 是否必选 | 类型 | 描述 |
|---|---|---|---|
| url | 必选 | string | 需要渲染的页面的url |
| timeout | 可选 | float | 渲染页面的超时时间 |
| proxy | 可选 | string | 代理服务器地址 |
| wait | 可选 | float | 等待页面渲染的时间 |
| images | 可选 | integer | 是否下载图片,默认为1 |
| js_source | 可选 | string | 用户自定义的JavaScript代码,在页面渲染前执行 |
execute端点
在爬取一些页面的时候,我们想在页面中执行一些用户自定义的JavaScript代码,可以通过利用Splash的execute端点来实现
| 服务端点 | execute |
|---|---|
| 请求地址 | http://localhost:8050/execute |
| 请求方式 | POST |
| 返回类型 | HTML |
execute支持的参数如下表所示
| 参数 | 是否必选 | 类型 | 描述 |
|---|---|---|---|
| lua_source | 必选 | string | 用户自定义的lua脚本 |
| timeout | 可选 | float | 渲染页面的超时时间 |
| proxy | 可选 | string | 代理服务器地址 |
我们可以将execute端点的服务看作是一个可以用lua语言编程的浏览器,使用时需要传递一个用户自定义的lua脚本给Splash,该lua脚本中包含用户想要模拟的浏览器行为,例如:
- 打开某url地址的页面
- 等待页面加载或渲染
- 执行JavaScript代码
- 获取HTTP响应头部
- 获取Cookie
用户自定义的lua脚本中必须包含一个main函数作为程序的入口,main函数被调用的时候会传入一个Splash对象(lua中的对象),用户可以调用该对象上的方法操纵Splash
在Scrapy中使用Splash
如果我们需要在Scrapy中调用Splash服务,Python的scrapy-splash库是非常好的选择
我们在安装好Python包之后,需要在settings.py中对其进行配置
1 | # 渲染服务的url |
然后再编写代码爬取网页(以百度知道为例)
1 | import scrapy |
存入数据库
我们在爬取到数据之后,有些时候需要将其存储到数据库中
SQLite
SQLite是一个轻量级数据库,在数据量很小的情况下,它的处理速度很快,使用它足够了
SQLite数据库的文件创建和表创建在此不做赘述
在Python中,可以使用Python标准库的sqlite3模块去访问SQLite数据库
在配置文件settings.py时,我们需要指定所要使用的SQLite数据库,并启用和SQLite相关的Pipeline
1 | SQLITE_DB_NAME = 'scrapy.db' |
MySQL
MySQL的应用极其广泛,它是开源免费的,可以支持大型数据库,是个人用户和中小企业的技术首选
此次仍然不赘述MySQL数据库的创建和表的创建
Python可以使用mysqlclient模块访问MySQL数据库
在配置文件settings.py时,我们需要指定所要使用的MySQL数据库,并启用和MySQL相关的Pipeline
1 | MYSQL_DB_NAME = 'scrapy_db' |
MongoDB
MongoDB是一个面向文档的非关系型数据库,近年来得到了广泛应用
Python可以使用pymongo模块访问MongoDB数据库
在配置文件settings.py时,我们需要指定所要使用的MongoDB数据库,并启用和MongoDB相关的Pipeline
1 | MONGODB_URL = 'mongodb://localhost:27017' |
Redis
Redis是一个使用ANSI C编写的高性能Key-Value数据库,使用内存作为主存储
在Python中可以使用redis-py访问Redis数据库
在配置文件settings.py时,我们需要指定所要使用的Redis数据库,并启用和Redis相关的Pipeline
1 | REDIS_HOST = 'localhost' |
使用HTTP代理
HTTP的代理服务器可以比作客户端和服务器之间的一个信息中转站,客户端发送的HTTP请求和Web返回的HTTP响应通过代理服务器转发给对方
HttpProxyMiddleWare
Scrapy内部提供了一个下载的中间件HttpProxyMiddleWare,专门用于给Scrapy爬虫设置代理
默认情况下,HttpProxyMiddleWare是启用的,它会在系统的环境变量中搜索当前的系统代理(名字格式为xxx_proxy的环境变量)作为Scrapy爬虫所使用的代理
多个代理
当利用HttpProxyMiddleWare进行代理的时候,对于一种协议(HTTP或HTTPS)的所有请求只能使用一个代理,如果想使用多个代理,可以在构造每一个Request对象时,通过meta参数的proxy字段手动设置
随机代理
某些网站为了反爬虫,经常会监测IP的访问量,如果同一IP在短时间内大量访问的话,服务器会将其封禁
爬虫可以使用多个代理对此类网站进行爬取,此时的访问量会被多个代理所分摊,从而避免封禁IP
我们只需要在middlewares.py中实现随机使用代理的算法即可
分布式爬虫
由于受到计算能力和网络带宽的限制,单个计算机上运行的爬虫在爬取的数据量较大的情况下,需要耗费较多的时间
scrapy-redis库为Scrapy拓展了分布式爬取的功能,可以让网络中的多台计算机上同时运行爬虫程序
